Database Design Tutorial for Beginners
Updated Databases
Table of Contents
Databases are at the heart of every web application. Their design, or schema, is literally the blueprint for how all information is stored, updated, and accessed. However, learning about databases is difficult. There are many long, complicated books on database theory but few simple explanations for beginners.
This is a tutorial on database design for beginners. It is the database primer I wished existed when I was starting out.
What is a Database?
A database is a program that allows for the storage and retrieval of data. Broadly speaking, there are two types of databases: relational and non-relational.
Relational databases, which are far more common, consist of tables that are structured in columns and rows, similar to an Excel spreadsheet. Popular database options, including MySQL, PostgreSQL, Microsoft Access, Microsoft SQL, and Oracle, are relational. They use SQL (Structured Query Language), which is a programming language just for managing data in a relational database.
By contrast, non-relational databases do not have a strict column and row schema. Proponents view them as “more flexible” than their relational counterparts, and they are commonly used for large-scale or unstructured data scenarios such as document storage, real-time analytics, and caching. MongoDB is a popular example and has official support in Django.
This tutorial will cover relational databases. If you’re new to databases, this is the easiest place to start.
Tables and Primary Keys
A database is made up of (often multiple) tables. A simple table, let’s call it customers, would look like this:

The columns are “customer_id,” “username,” “email,” “password,” and “birthday.” Each row is known as a record. As the number of users grew, we could eventually add hundreds or even millions of records, but the defined columns would stay the same.
The “customer_id” column is what’s known as a primary key: a unique and non-null number that refers to each record. Every record/row in a relational table has a primary key.
To understand why, let’s imagine that the user “william” wants to change his “username” to “bill.” How do we know which “password” and “birthday” to associate with this user? Without a primary key, we don't.
Tables also become much, much more complicated over time. A primary key gives us a unique way to identify and manage each record.
Data Redundancy and Input Constraints
A key tenet of good database design is that each data item, for example, a username, should only be stored once in one location. This avoids having to maintain and update multiple locations, which is very error-prone.
A second tenet is to use input constraints to increase the reliability of your data. For example, in our “email” column, we know that a proper email record should contain the “@“ symbol, so we can say that only data with the “@“ symbol can be entered. In the birthday column, we want a date datatype here, so only birthdays entered with numbers will be accepted.
Linking Tables with Foreign Keys
When designing a database, the key decisions are what data you want to store and what relationship exists between them. Right now, we just have a customers table, but let’s say we also want to store orders because we’re building an e-commerce website.
It’s tempting to think we can just add a column for orders to our existing table. But an order has multiple pieces of information we want to track. For example, at a minimum, we’d want to know:
- the order_id (primary key) so we can keep track of each order
- the date and time the order was placed
- the customer the order was placed by
This means we need a separate table for Orders. In order to associate a specific order with a specific customer, we can use a foreign key relationship through the customer_id field to link the two tables.
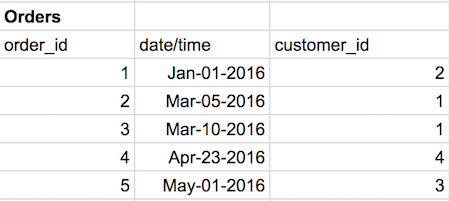
If we look at the Orders table schema we can see the first order was placed by customer_id 2, “john” in the Customers table. The next order, order_id 2, was made by "william." And so on. Foreign keys let us link multiple database tables together.
One-to-many, one-to-one, and many-to-many relationships
There are three types of foreign key relationships. The first, one-to-many, is what we have with the customers and orders tables. One customer can place multiple orders. By using the customer primary key as our foreign key in the orders table, we can keep track of this.
An example of a one-to-one relationship would be a database tracking people and passports. Each person can only have one passport, and vice versa, so those two tables would have a one-to-one relationship.
The third option is known as a many-to-many relationship. Let's imagine we have a database tracking authors and books. Each author can write multiple books, and each book can have multiple authors. Implementing this requires an intermediary table (sometimes called a junction or through table) that holds foreign keys to both the authors and books tables, allowing each pair to be linked without duplicating data in either table.
Database Normalization
Designing a database is both an art and a science. As needs change over time, a database will undergo frequent updates to its table and column layout. Unfortunately, redundant data can often sneak in, which causes multiple problems:
- inefficient - the database engine will need to process more data for each query or update
- bloated - storage requirements increase due to redundant data
- errors - redundant data must be manually inputted, which is error-prone
Normalization is the formal term for the process of eliminating redundant data from database tables. There are five normal forms, but most database designers stop at levels 2 or 3 because while normalization reduces data dependency, it comes with added complexity that decreases performance.
Next Steps
Now that you've learned the basics of database design, why not try building a few database-driven websites yourself with Django? To learn how Django models map to database tables, check out the Django Best Practices: Models tutorial. To learn how to query and manipulate that data using Python, see the Django ORM and QuerySets Tutorial. If you'd like a deeper look at database design, the best book I know of is Database Design for Mere Mortals.